![Features of the SML Model [34].](https://www.researchgate.net/profile/Nazmul-Hossain-3/publication/377852289/figure/fig4/AS:11431281221462482@1706782352337/Features-of-the-SML-Model-34_Q320.jpg)
Content uploaded by Nazmul Hossain
Author content
All content in this area was uploaded by Nazmul Hossain on Feb 01, 2024
Content may be subject to copyright.
ISSN: 2320-5407 Int. J. Adv. Res. 12(01), 422-438
422
Journal Homepage: -www.journalijar.com
Article DOI:10.21474/IJAR01/18138
DOI URL: http://dx.doi.org/10.21474/IJAR01/18138
RESEARCH ARTICLE
CLASSIFYING THE SUPERVISED MACHINE LEARNING AND COMPARING THE PERFORMANCES
OF THE ALGORITHMS
Rathindra Nath Mohalder1, Dr. Md. Alam Hossain2 and Nazmul Hossain3
1. Research Scholar, Department of Computer Science and Engineering, Jashore University of Science and
Technology.
2. Professor, Department of Computer Science and Engineering, Jashore University of Science and Technology.
3. Assistant Professor, Department of Computer Science and Engineering, Jashore University of Science and
Technology.
……………………………………………………………………………………………………....
Manuscript Info Abstract
……………………. ………………………………………………………………
Manuscript History
Received: 11 November 2023
Final Accepted: 14 December 2023
Published: January 2024
Key words:-
SL, SML, AL, ML, ANN, KNN, DT,
SVM, KD, KDD, IDA, SLM
Supervised Learning (SL), also recognized as SML, means Supervised
Machine Learning. It‘s a subclass of AI (Artificial Intelligence) and
Machine Learning (ML). It's defined by the conduct of entitled datasets
for training algorithms that predict outcomes precisely or classify data.
The input dataset is faded into the supervised Machine Learning model,
which synthesizes its weights until the model has been fitted properly,
which happens as a segment of the cross-validation process. Supervised
learning machine assists organizations in solving different kinds of
real-world problems. SML is searching for algorithms that externally
outfitted the instances to produce common hypotheses, preparing
predictions for future cases.The supervised Machine Learning (SML)
classifications are frequently completed tasks by effective intelligent
systems. This paper discusses different categories of Supervised
Machine Learning classification technology, compares different
categories of supervised learning algorithms and identifies the best
effective classification algorithm based on some instances, data set and
variables or features. This paper discusses eight different types of SML
algorithms. Those were envisaging: Artificial Neural Network (ANN),
Bayesian Networks, K-nearest Neighbor (KNN), Random Forest,
Decision Tree (DT), Linear Regression, Support Vector Machine
(SVM), and Logistic Regression.These eight algorithms develop in the
python language. Using a sample dataset for every algorithm and
justify the algorithm performance. Here, justify the algorithms based on
three different outcomes: throughput, response time, and accuracy. The
supervised learning method depends on pre-defined parameters. The
performance metric has an important role in identifying the ability and
capacity of any kind of machine learning algorithm. The outcomes
show that Decision Tree is the best prediction performance in this paper
and gives the best accuracy, response time and throughput. The next
accurate algorithms in SML algorithms are Logistic Regression and
SVM after the DT algorithm.
Copy Right, IJAR, 2024,. All rights reserved.
Corresponding Author:- Nazmul Hossain
Address:- Assistant Professor, Department of Computer Science and Engineering,
Jashore University of Science and Technology.
ISSN: 2320-5407 Int. J. Adv. Res. 12(01), 422-438
423
……………………………………………………………………………………………………....
Introduction:-
For a long time, various ML algorithms have been effectively used for creating predictive casts from the dataset. ML
algorithms and data mining tools in expert-based disciplines are knowledge-intensive and data-rich. In the recent-
day, the information society is growing rapidly. Computers affect all strategies in society, such as medical research
and economy, and typically extrude the manner human function and penetrate new regions of practice. They look at
recent statistics technology and its utility in specific regions resulting in the advent and improvement of
contemporary-day programming languages and structures [1].
Figure 01:- The Method of SML [6].
In general, it was studied within the context of numerous disciplines –– DM (data mining), IDA (intelligent data
analysis), KDD (Knowledge discovery in databases), and ML (machine learning). In trend, KDD studies worry
about the whole Knowledge invention process, such as data mining, pre-processing and post-processing.
Contrariwise, ML studies have many opportunities--it researches the studying system and, in several, the automatic
studying system.
Notwithstanding all four fields' making large developments in automatic information achievement from data, they've
now no longer at once searched the labyrinth of ambit knowledge integration in another all of KD method. ML is the
fastest developing computer science and engineering sector, with large-extending application programs. It means the
self-acting discovery of significant swatches in a dataset. ML instruments are related to awarding projects which
might adapt yet learned [2]. The ML method has formed on the mainframes of a principal portion of our existence,
albeit usually hidden and Information technology. With the increasingly huge amount of data fitting available for the
best reason, I believe that dataset analysis will happen more as an important component for technical systems.
ISSN: 2320-5407 Int. J. Adv. Res. 12(01), 422-438
424
Mobs are often apt to possibly build errors during analyses when attempting to set up relevance among multiple
features [3]. Machine Learning and Data Mining are similar pairs where different sagacity can be evolved with
accurate learning methods. New data creation makes ML methods more realistic from day today. It is used for
individual methods for both unsupervised and supervised MLis rationally collective in the classification matters sod
that the aim is to get the computational system to study the classification technique that we made [4]. Machine
Learning is properly aimed at achieving accessibility invisible between large data.
ML is appropriate for the angularity of monitoring through different data roots, yet the huge extent of values with
huge amounts of data worried machine learning improves raising datasets. With the freedom from the lines of a
particular level of study and concern, machine learning is cute to search out and display the models mystic in the
dataset [5].
ML is the fastest developing computer science and engineering sector, with large-extending application programs. It
means the self-acting discovery of significant swatches in a dataset. ML instruments are related to awarding projects
which might adapt yet learned [2]. The ML method has formed on the mainframes of a principal portion of our
existence, albeit usually hidden and Information technology. With the increasingly huge amount of data fitting
available for the best reason, I believe that dataset analysis will happen more as an important component for
technical systems. Mobs are often apt to possibly build errors during analyses when attempting to set up relevance
among multiple features [3]. Machine Learning and Data Mining are similar pairs where different sagacity can be
evolved with accurate learning methods. New data creation makes ML methods more realistic from day today. It is
used for individual methods for both unsupervised and supervised ML the SML is rationally collective in the
classification matters sod that the aim is to get the computational system to study the classification technique that we
made [4]. Machine Learning is properly aimed at achieving accessibility invisible between large data. Machine
learning hands over the surety of taking out valorizes from distinct and big data roots, although bordering on less
dependence scheduled on separate tracks as its data spurts and determined at machine range.
ML is appropriate for the angularity of monitoring through different data roots, yet the huge extent of values with
huge amounts of data worried machine learning improves raising datasets. With the freedom from the lines of a
particular level of study and concern, machine learning is cute to search out and display the models mystic in the
dataset [5].
Standard manufacture of SLM load is a classification matter: Learner is needed to study (probable the nature) a
function that designs a vector with different classes by finding different input-outcome instances of functions.
Inducing ML is a system of knowledge that is a part of laws from cases (training dataset), or moreover usually
creating, telling a classifier which will be conducted to normalize from recent precedents. The system of enforcing
SML in an actual problem is related in Figure 1. This work focuses on different types of machine learning methods
and identifies the best efficient algorithm with strong accuracy, throughput, and response time.
The Supervised Machine Learning Algorithms Classification: -
Following [7], SML methods/algorithms are conducted much with the classification encircles due to Artificial
Neural Networks, Bayesian Networks, Decision Tree, K-nearest Neighbor, Support Vector Machine, Random
Forest, Linear Regression and Logistic Regression and others.
ISSN: 2320-5407 Int. J. Adv. Res. 12(01), 422-438
425
Figure 02:- Artificial neural network (ANN) architecture.
Artificial Neural Network (ANN):
Recently, a multitude of methodologies and ideas from individual disciplinarian fields have increased in particularly
attractive research field ANN [8]. A neuron is a basic unit for making the nervous networks which perform
communication and computational methods. The ANN is the working repetition of the facilitated method of the
biologic neuron. Yet, the aim is to reconstruct knowing data appraisal methods like classification, generalization,
and pattern recognition using simple distributed and robust processing units named Processing Elements (PE) or
artificial neurons [9]. A chief benefit of the ANN access is that the ambit learning gives shares in neurons. Data
processing is brought to pass in a collateral distributed manner [10]. ANNs are exceptionally collateral data
processing instruments able to learn the working dependencies of the dataset [8]. They have to be able to clearly
categorize a high non-linear bearing yet, once trained, can categorize fresh datasets so much more swiftly than it
should be probable by proving the structure logically. ANN formation is based on artificial neurons.
Every artificial neuron features a system node (‗body‘) delineated by circles within the figure likewise as affiliations
from (‗dendrites‘) and affiliations to (‗axons‘) alternative neurons that are shown as arrows sign in the figure 02. In
the last step, the output neuron gets the weighted aggregate of inputs and dispenses the non-linear functionality to
the weighted aggregate. The results of this function make the outcome for the complete ANN [11].
ISSN: 2320-5407 Int. J. Adv. Res. 12(01), 422-438
426
Figure 03:-Possible hierarchical Bayesian network structures. The gray-colored nodes represent the latent variables
and the white-colored nodes represent the observed variables.
Bayesian Networks (BNs):
An essential step for developing artificial sagacity is to qualify an engine to describe how the universe acts by
constructing an interior model from a dataset. A very important view is studying the dependency diagram of BNs
from a dataset. The motive defines learning the structure, is called NP-solid [12], and yet is chopping-edge research
object acute. Shortly, it is knowledge of as selecting a diagram depends on a few candidates, mounting the argument
all over the gathering of patterns of the format producing dataset. A wide review of remaining software instruments
is also conferred [13]. The main argument in artificial intelligence is developing structures that enable generating a
model narration of the ambit wisdom yet receiving within calculation the most probably structures will learn from
the dataset.
BNs is a DAG (directed acyclic graph). Where conditional dependencies on edges and the random variables are
represented by nodes. Now the Bayes‘ Theorem equation is:
P(H|E) = PHP(E|H)
PE
Here, P(H|E)= Posterior probability of ‗H‘given the evidence; P(H)= Prior Probability; P(E|H)= Linklihood of the
evidence ‗E‘ if the Hypothesis ‘H‘ is true; P(E)=Priori probability that the evidence itself is true.
The strict HBN and loose HBN were received for supervised classification of instances and for designing of
variables [14].
Dicision Tree (DT):
DT is one of the significant technologies in machine learning. Several sectors applied the Decision Tree algorithm
and applied it in several applications. Decision Tree has three different algorithms that are C4.5, CART and ID3
[15]. The ramification is the motive of offering objects to the class, which has various applications.A normal tree
comprises roots, leaves and branches. It's a predictive structure applied in machine learning, data mining and
statistics. In tree models, the destination variable can get a limited set of entities that are defined as classification
trees; in the tree model, leaves represent the label of branches, and class represents the joins of fertilities that
conduct with those labels of class. Decision trees can construct comparatively faster than any other method of
classification [16].
Decision tree is similar to the tree. To construct a tree, uses the CART (Classification and Regression Tree
algorithm). The structure of the decision tree:
ISSN: 2320-5407 Int. J. Adv. Res. 12(01), 422-438
427
A group of analysis used to analogy the performance of every algorithm. This added the boosted/tuning DT
Regression. Tuning/boosted DT regression is the algorithm applied to train model by performing with Multiple
Additive Regression Trees (MART) algorithm. Every tree is devoted on prior trees that represents how to
boost/tuning works shown in Figure 04[17].
ISSN: 2320-5407 Int. J. Adv. Res. 12(01), 422-438
428
Figure 06:- Architecture of support vector machine.
D. Support Vector Machine (SVM):
SVM is the significant ML algorithm usually developed in pattern recognition problems, classifying the image
processing and network traffic for recognition.
Too much research is working on skilling to develop Quality of Service (QoS) and indemnity aspects. Recent work
in this sector has been solved by SVM. It acts more finely than any other classification network traffic for
normalizing the difficulty. This research represents the aspect of SVM, its applications and its concepts overview
[18]. SVM is the strong learning method applied in binary classification. The SVMs principle task is to search for
the greatest hyper plane which can differentiate data properly into twice classes. [19]. Nowadays, multi-class
classification was gained by mixing multiple binary support vector machines. The architecture of SVM is shown in
figure. 06.
E.K-nearest Neighbor (KNN):
Distance-basis algorithms are broadly used for dataset classification difficulty. The KNN classification is the most
exoteric distance-basis algorithm.Euclidean distance by this behavior of different datasets requires private
resemblance measurement accommodated to the dataset features. [20] Alignment is the SML system that graphs on
the input dataset, defining classes/groups. The main principle argument for investing an arrangement rein is that all
of the dataset aims would be engaged to the groups and that every entity object would be engaged to a single group.
Here, K use as an amount of the closest neighbors in KNN.
F. Linear Regression:
One of the maximum general, extensive statistical and ML algorithms is linear regression. It's applied to identify
linear relationships within once or farther identifiers. Two types of linear regression: multiple regressions (MLR)
and simple regression. Different researchers are researching polynomial, and linear regression yet compares their
effectiveness using the accession to optimistic precision and prediction [21].
Machine learning [22-23] is generally conducted in diverse sectors to solve various problems that can't be smoothly
composed depending on computer direction. Linear regression [24] is the mathematical experiment conducted for
quantifying and evaluating the familiarity into the calculated attributes. Therefore, sketchy regression and
correlation are experiments where a boffin in perception the bonding into two attributes to count the influence of
ISSN: 2320-5407 Int. J. Adv. Res. 12(01), 422-438
429
disorders [22, 25, and 26]. Linear regression [27] is generally conducted in mathematical techniques. It‘s likely to
identify the prediction model yet affect the versus multiplex input attributes.
Figure 07:-K-nearest Neighbour (KNN) algorithm workflow.
Now consider Figure 8.1 an architecture model of the linear regression, as a forerunner of the neural network. Sum
of the weighted is presented as computational unit. Here‘s a consecutive convention considering the favor as few
specific weights, having the corresponding node as input and also constant noted value is +1[28].
The Linear regression has also been normalized to multi-variation linear regression. In this case, multiple variables
y1, ....... yp for prediction, as represented in Figure 8.2 (as an example, 3 prediction variables use y1, y2, y3) [28].
Figure 8.1:- Architectural model of linear regression.
ISSN: 2320-5407 Int. J. Adv. Res. 12(01), 422-438
430
Figure 8.2:- Architectural model of multi-variation linear regression.
Figure 09:-Architecture of a Logistic Regression Model.
Logistic Regression:
Logistic regression has broadly applied to different fields of the experiment, such as hygiene science, to learn the
risk factor attached to the illness. Some surveys depending on Health Survey and Demographic are made predicting
mixed modeling i.e., multistage sampling, stratified and probabilistic with unbalanced magnification in the survey.
These compound diagrams must hold to calculate faithful outcomes. Although it is a relevant general issue and not
well analyzed in the literature [29].
It is the preferential probabilistic structure. This structure generates inferior probability formation P(Y|X),(Y =
destination variable and X = features). Given X, return to a probability formation over Y. In Figure 09represents an
architecture model of the logistic regression. Outcome of the sigmoid function is explained as probability of
individual sample including to the positive class, in the binary classification crux. An example, Z=
Py = 1x; w(Z = linear combination of the weights and the samples features Z = wTx. This algorithm is broadly
used for classification. This algorithm is broadly used for classification[30].
ISSN: 2320-5407 Int. J. Adv. Res. 12(01), 422-438
431
Figure 10:- Random forest Architecture.
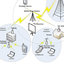
Figure 11:- Features of the SML Model [34].
H. Random Forest (RF):
Random Forest algorithm is an assemble method which combined the outcomes of various randomly built
classification tree. Two elements of randomness are proposed into the building of the several trees. At Frist, every
tree is built using the random bootstrapped form of training dataset. Prediction contracts for unobserved dataset by
getting a majority view of the individual trees. Random Forest packages in python used for implementation [31]. In
RF for constructing a tree uses random dataset. Figure 10 shows the Random Forest model architecture. Random
forest is generated the prediction result by the average all sub-tree predictions.
ISSN: 2320-5407 Int. J. Adv. Res. 12(01), 422-438
432
Features of supervised Machine Learning Algorithms:
SML methods are contextual to mass ambits. Some ML dispensation oriented researchers can get in [32], [33]. In
general, neural networks and SVMs bend to deduct better, however, conduct with continuous features and multi-
tasking. However, other sites' logic-basic methods bend to enact so well, conducting with definite characteristics.
For SVMs and ANN models a huge pattern is needed in sequence to gain its maximal accuracy count where Naive
Bayes can require a comparatively little dataset.
Figure 12:- SML working process [36].
Related Works:-
An SML model has two portions: one is the training part and another is the testing part. In the training part, sample
datasets are taken into training as input. Which characteristics are realized by the learner or which learning
algorithm constructs the learning model [35]. On the other hand, the testing part, the learning structure, conducts the
redaction engine, making the count for producing or testing data. Tied datasets are the model's main outcome, which
generates the ultimate classified /prediction data.
The SML process (figure 12) is a common method in classification matters, although the machine aims to learn
about the classification model we have constructed.
In the classification, the entities are abstract, in regression, the label is continual. In this research data was reached
from BMI calculation chart. This dataset was selecting because of its accuracy and has also been anonym zed (de-
identified), therefore confidentiality is ensured.
In this research number of Columns 4 and number of row 1128 .So number of 4512 instance for using as a datasets.
In the four columns are height, weight, BMI, and outcome a result which is depends on another three columns
instance. Here uses the height as a centimeter scale and weight data gets in pound scale. This height and weight are
integer type‘s data and BMI is floating type‘s data. But on the other hand, the outcome result or the destination
result columns are String type datasets. For getting proper outcomes iterates every models 100 times and takes the
average outcome result as the final result.
Proposed Efficient Model:-
In this research have two vital objectives: At first, makes a compare of some supervised machine algorithms:
Random Forest, Support Vector Machines, Naive Bayes, K-near Neighbor (KNN), Logistic Regression, Linear
Regression, Artificial Neural Networks (ANN) and Decision Trees. And other important goal is improve the
accuracy of final results using hyper parameter tuning and cross validation. The architecture of the proposed
approach can be seen in Figure no. 13.
(i) Comparison of Methods
This paper discus about eight supervised machine algorithms performance based on the algorithms accuracy,
Response time and Throughput. We target an algorithm is best which accuracy and throughput is high and response
ISSN: 2320-5407 Int. J. Adv. Res. 12(01), 422-438
433
time is low. In this research we get significant outcome on throughput, response time and accuracy from different
supervised machine learning algorithm.
(ii). Proposed Model
In this research analytical part we find vital outcome on accuracy, response time and throughput. Different
supervised machine learning algorithms gives different kind of performance which based on throughput, response
time and accuracy. In this research, two different algorithms Random Forest and Decision Tree generates best
outcomes. It‘s to be noted that, Random Forest generated accuracy is high that is near about 93.36% but its response
time and throughput performances are low. One the other hand, Decision Tree generates second higher accuracy is
near about 90.71% and its response time and throughput performances are high.
Figure 13:- Proposed Model using hyperparameter tuning.
In this situation, we used proposed methods for getting a best algorithm form those supervised machine learning
algorithms. Now focus on two algorithms Decision Tree and Random Forest. The Random Forest accuracy is high
but its response time and throughput performances are low. On other hand, the Decision Tree generates second
higher accuracy and its response time and throughput performances are high. So at this moment, we want improve
the Decision Tree accuracy using hyperparameter tuning and cross validation Model.
Hyperparameter tuning and cross validation for an algorithm is normal method that uses for increasing algorithm
performances.Hyperparameters are naturally adjusted before the real training method begins.
It‘s done by engaging various values for that hyperparameters, training model, and improving accuracy of ours
targeted algorithms. The tuning of hyperparameter is a method for selecting the particular combination of the
hyperparameters depends on the performance of current data. It‘s a fundamental necessity for getting accurate and
meaningful outcomes from machine learning algorithms. Following figure no. 13 represents things to consider, the
model tuning method, and workflow.
Rotation estimation is also known as Cross-validation (CV). It is the model validation method for measuring the
efficiency of the results and statistical analysis. The aim is to create the model normalized toward a random test set.
It helps to estimate which way model can predict and it will perform accurately in machine learning application.
Using cross-validation method, a model is normally trained with dataset of a acquainted type. Moreover, it‘s tested a
dataset which is unknown variant. In this aim, CV helps to narrate a dataset testing the model in training stage using
validation set.
ISSN: 2320-5407 Int. J. Adv. Res. 12(01), 422-438
434
Hyper-parameters are a significant sector for model performance analysis which set appropriate values to improve
model efficiency. These research hyper-parameters use GridSearchCV to find out optimal values for getting the
model's best performance.
GridSearchCV is a method of executing hyper-parameter tuning for identifying optimal values for selecting the
model. In GridSearchCV checks, all types of combos of values arrived at the dictionary so that estimate the
algorithm for every combo using the Cross-Validation technique. Using this technique get loss/accuracy for each
combo of the hyper-parameters and choose the best performance generating optimal combo values.
The model‘s parameters configuration is native to the model. Prediction needs to use these parameters. Those are
guessed or specified when the method trains up. It‘s an internal part of a model. It‘s set and learned by the model.
The model‘s parameters configuration is native to the model. Prediction needs to use these parameters. Those are
guessed or specified when the method trains up. It‘s an internal part of a model. It‘s set and learned by the model.
On the other site, hyper-parameters are that parameters are explicitly controlled and specified in the training method.
This research finds the optimal values using the GridSearchCV method for hyper-parameters tuning to get the best
performance of our model.
Evaluation of methods results and Efficiency Analysis:-
Results:-
Table 1:- Eight Supervised Learning Method and Proposed Model performances table on a sample dataset.
Figure 14:-Eight supervised learning methods and proposed model accuracy graph.
No.
Algorithm‘s Name
Throughput
Response Time(millisecond)
Accuracy
(100%)
1
Proposed Model
110874.5251
0.001990
95.13%
2.
Decision Tree
112873.6251
0.001993
90.71%
3.
Random Forest
11886.35081
0.018929
93.36%
4.
Support Vector Machine(SVM)
12546.826
0.017933
90.27%
5.
K-near Neighbor (KNN)
14116.13683
0.015939
88.05%
6.
Logistic Regression
75621.27675
0.002975
84.51%
7.
Naive Bayes
15055.07527
0.014945
79.65%
8.
Linear Regression
75284.94194
0.002989
57.96%
9.
Artificial Neural Networks(ANN)
3893.936746
0.057782
53.10%
ISSN: 2320-5407 Int. J. Adv. Res. 12(01), 422-438
435
Accuracy
Accuracy directs to the sanctification of an individual measurement. Accuracy is destined by assimilating the
measurement versus the accepted or true value. The accurate measurement is closer to the truth value.
Figure 15:- Eight supervised learning methods and proposed model Response time graph.
Response time
The time season between a marginal operator's depletion of an investigation and the getting a response. The
response time involves the time taken to send the inquiry yet process it by the methods and send the feedback to the
marginal. The response time is usually used for measuring the reduction of interactive algorithms.
Figure 16:- Eight supervised learning methods and proposed model throughput graph.
ISSN: 2320-5407 Int. J. Adv. Res. 12(01), 422-438
436
Throughput
Throughput is the calculation of how much data a method can process in a given number of times. Connected
calculation of algorithm productivity comprises the speed across which few tangible workloads can be fulfilled. The
response time is the extent of time into an individual interactive user desire and getting the response times.
Discussion:-
In table. 01, we see eight (08) supervised learning methods (ANN, Bayesian Networks, DT, KNN, SVM, Random
Forest, Linear Regression and Logistic Regression) and proposed model. A sample dataset and implement python
coding to notify eight supervised learning methods and proposed model. We determine all supervised learning
method throughput, the Response time (millisecond), and accuracy (100%) through the process. Every supervised
learning method gives its individual operation performance, providing our perfect outcome. By this performance
analysis, we get proposed model method is best among eight methods.In figure no. 14, the graph shows that the best
accuracy is proposed model about 95.13%. Secondly high accuracy is Random Forest that is about 93.36% and the
worst accuracy is ANN – 53.10%. For getting best accuracy we use hyper-parameter tuning with Cross- validation
technique. At the final outcome, we get that proposed model gives the best result in our dataset.
Conclusion and Future Work:-
Machine learning ramification needs detail subtle to the constants and, at that time, a large number of cases for the
dataset. There is no problem constructing the structure for any method but the right classification. However, a better
learning method for a special dataset doesn't gaze at accuracy, throughput and response time for another dataset
whose characteristics are logically varied from others. Although the main point when we are in contact with
Machine Learning classification isn't in the case, a learning method is excellent for another. Still, an individual
model can significantly outcome from any other definite application matter beneath those situations. Meta-learning
is passing the way, trying to search functions that are designed with the dataset for algorithm execution. At last, it
uses several attributes defined as meta-attributes to display the behavior of studying works while finding the
interrelations among these attributes yet the learning algorithms reduction. Some behaviors of the learning works
are: the ratio of categorical attributes, total count of instances, entropy of classes, a ratio of missing values, etc.
Providing a comprehensive chart of statistical yet information calculates for datasets. Considering the limitations yet
strengths of every technique, the probability of perfecting two or extra methods simultaneously to prove matters
would be researched. The purpose is to improve the powers of one model to multiplier the debilitation of another. If
we focus on the best feasible classification on the accuracy, it is impossible and difficult to identify a singular
classifier that fulfills the best classification ensemble. SVM, DT and Logistic Regression algorithm can give upper
accuracy, response time and throughput of many data and attributes instances. ML algorithm requires the best
accuracy, minimum response time, and maximum throughput to have supervised machine learning.
This paper recommends a few sample datasets and predicts the target values in different supervised machine
learning algorithms. In the future, we have to work with different varieties of huge datasets and analyze the
performance of the SML algorithms that also depend on other different parameters.
References:-
1. Shafagat Mahmudova ―Analysis of Software Performance Enhancement and Development of Algorithm‖
International Journal of Innovative Science and Research Technology, Volume 4, Issue 1, ISSN No:-2456-
2165,(January – 2019).
2. Alican Dogana, Derya Birantb,―Machine Learning and Data Mining in Manufacturing‖Expert Systems with
Applications Volume 166, 114060,(15 March 2021).
3. Ritu Sharma, Kavya Sharma, Apurva Khanna.―Study of Supervised Learning and Unsupervised Learning‖,
International Journal for Research in Applied Science &Engineering Technology (IJRASET), Volume 8
Issue VI , ISSN: 2321-9653,(June 2020);
4. Keith A. Brown, Sarah Brittman, NicolMaccaferri, Deep Jariwala, and Umberto Celano, ―Machine Learning in
Nanoscience: Big Data at Small Scales‖,National Liabrary of Medicine Nano latters,pubs.acs.org/Nano
LettersDOI: 10.1021/acs.nanolett.9b04090, (January 2020).
5. Jose F. Rodrigues Jr, Larisa Florea, Maria C. F. de Oliveira, Dermot Diamond, Osvaldo N. Oliveira Jr, ―Big
data and machine learning for materials science‖ Discover Materials in Springer, published on (19 April,
2021).
ISSN: 2320-5407 Int. J. Adv. Res. 12(01), 422-438
437
6. Oluwakemi Christiana Abikoye, Gyunka Benjamin Aruwa ―he Threat of Split-Personality Android Malware on
Developing Economy‖ Published by University of the West of Scotland is a registered Scottish charity. Vol
22, No 1,Charity number SC002520,( 2018).
7. Mohammed H. Alsharif, Anabi Hilary Kelechi, Khalid Yahya and Shehzad Ashraf Chaudhry, ―Machine
Learning Algorithms for Smart Data Analysis in Internet of Things Environment: Taxonomies and Research
Trends‖ published in Symmetry, Symmetry 2020,12, 88; doi:10.3390/sym12010088, Published: (2 January
2020).
8. Egba. Anwaitu Fraser, Okonkwo, Obikwelu R, ―ARTIFICIAL NEURAL NETWORKS FOR MEDICAL
DIAGNOSIS: A REVIEW OF RECENT TRENDS‖ Published in International Journal of Computer Science
and Engineering Survey (IJCSES), Vol.11, No.3, (June 2020).
9. Roza Dastres and Mohsen Soori ―Artificial Neural Network Systems‖ International Journal of Imaging and
Robotics, [Formerly known as the ―International Journal of Imaging‖ (ISSN 0974-0627)] Volume 21; Issue No.
2; Int. J. Imag. Robot. ISSN 2231–525X; (Year 2021).
10. Brigitta Nagy, Dorián László Galata, Attila Farkas and Zsombor Kristóf Nagy, ―Application of Artifcial Neural
Networks in the Process Analytical Technology of Pharmaceutical Manufacturing—a Review‖ Piblished in
American Association of Pharmaceutical Scientists, in Springer, The AAPS Journal, Published online 14
June 2022).
11. Nida Shahid, Tim Rappon, Whitney Berta ―Applications of artificial neural networks in health care
organizational decision – making:A scoping review‖, Published on PLOS ONE, (February19,2019).
12. Marco Scutari,Claudia Vitolo, Allan Tucker, ―Learning Bayesian networks from big data with greedy search:
computational complexity and efficient implementation‖ Published in Statistics and Computing (2019)
29:1095–1108, Content courtesy of Springer Nature, Published online: (15 February 2019).
13. Mauro Scanagatta, Antonio Salmerón, Fabio Stella3‖ A survey on Bayesian network structure learning from
data‖ Springer-Verlag GmbH Germany, part of Springer Nature 2019Progress in Artificial Intelligence,
Received: 14 March 2019 / Accepted: 20 May 2019. https://doi.org/10.1007/s13748-019-00194-y
14. Hasna Njah, Salma Jamoussi1Walid Mahdi, ―Deep Bayesian network architecture for Big Data mining‖
Published in WILEY, Concurrency Computat Pract Exper.( 2018);
15. Harsh H. Patel, Purvi Prajapati, ―Study and Analysis of Decision Tree Based Classification Algorithms‖,
International Journal of Computer Sciences and Engineering Open AccessResearch Paper Vol.-6, Issue-10,
Oct. 2018 E-ISSN: 2347-2693. Published: (31/Oct/2018)
16. Puvvada Hruthik, Sai Nivas Rao, Tuta Sri Sai Kailash, Akula Bala Chandra, Chavi Ralha ―MEAL PLAN
PREDICTION USING DECISION TREE CLASSIFIER: A REVIEW‖ Published in International Research
Journal of Modernization in Engineering Technology and Science, Volume:04/Issue:05/May-2022, e-ISSN:
2582-5208,(May-2022).
17. Jean-Pierre Briot, Ga¨etan Hadjeresand Franc¸ois Pachet; ―Deep Learning Techniques for Music Generation– A
Survey‖ Published in Cornil UniversityFrance, arXiv:1709.01620v1 [cs.SD],(5 Sep 2017).
18. Jair Cervantes, Farid Garcia-Lamont, Lisbeth Rodríguez-Mazahua, Asdrubal Lopez, ―A comprehensive survey
on support vector machine classification: Applications, challenges and trends‖ Published in Elsevier
Neurocomputing, Volume 408, Pages 189-215, (30 September 2020).
19. N. Chandra Sekhar Reddy, Purna Chandra Rao Vemuri , A. Govardhan , ―An Empirical Study on Support
Vector Machines for Intrusion Detection‖, International Journal of Emerging Trends in Engineering
Research, Volume 7, ISSN 2347 – 3983, No.( 10 October 2019).
20. Najat Ali, Daniel Neagu, Paul Trundle―Evaluation of k‑nearest neighbour classifier performance for
heterogeneous data sets‖ published in springer nature journal, Published online: (6 November 2019).
21. Dastan Hussen Maulud, Adnan Mohsin Abdulazeez ―A Review on Linear Regression Comprehensive in
Machine Learning”, Journal of Applied Science and Technology Trends Vol. 01, No. 04, pp. 140 –147,
(2020).
22. D. Q. Zeebaree, H. Haron, A. M. Abdulazeez, and D. A. Zebari, "Machine learning and Region Growing for
Breast Cancer Segmentation," International Conference on Advanced Science and Engineering (ICOASE),
2019, pp. 88-93, in (2019).
23. Bargarai, F., Abdulazeez, A., Tiryaki, V., & Zeebaree, D.‖ Management of Wireless Communication Systems
Using Artificial Intelligence-Based Software Defined Radio.‖ International journal of Interactive Mobile
Technologies, iJIM ‒ Vol. 14, No. 13, (2020).
24. D. M. Abdulqader, A. M. Abdulazeez, and D. Q. Zeebaree, "Machine Learning Supervised Algorithms of Gene
Selection: A Review‖, Technology Reports of Kansai UniversityISSN: 04532198 Volume 62, Issue 03,
(April, 2020).
ISSN: 2320-5407 Int. J. Adv. Res. 12(01), 422-438
438
25. Zebari, D. A., Zeebaree, D. Q., Abdulazeez, A. M., Haron, H., & Hamed, H. N. A., ―Improved Threshold Based
and Trainable Fully Automated Segmentation for Breast Cancer Boundary and Pectoral Muscle in Mammogram
Images‖ IEEE Access, 8, 203097-203116. Published:(2020).
26. Abdulazeez, A, M. A. Sulaiman, and D. Q. Zeebaree ―Evaluating Data Mining Classification Methods
Performance in Internet of Things Applications," Journal of Soft Computing and Data Mining, vol. 1, pp. 11-
25, (2020).
27. H.-I. Lim, ―A Linear Regression Approach to Modeling Software Characteristics for Classifying Similar
Software," IEEE 43rd Annual Computer Software and Applications Conference (COMPSAC), pp. 942-
943, (in 2019).
28. Jean-Pierre Briot, Ga ¨ etan Hadjeres, Franc¸ois-David Pachet, ―Deep Learning Techniques for Music
Generation‖, Published in Springer,ISBN: 978-3-319-70162-2.eBook ISBN: 978-3-319-70163-9,Series
ISSN:2509-6575in (2019)
29. Ernest Yeboah Boateng and Daniel A. Abaye, ―A Review of the Logistic Regression Model with Emphasis on
Medical Research‖ Journal of Data Analysis and Information Processing, 7, 190-207, ISSN Online: 2327-
7203,ISSN Print: 2327-7211, (in 2019).
30. Renato Torres, Orlando Ohashi and Gustavo Pessin ―A Machine-Learning Approach to Distinguish Passengers
and Drivers Reading While Driving‖, Published in MDPI-Sensors, Sensors 2019, 19, 3174;
doi:10.3390/s19143174, (19 July 2019).
31. Bette Loef, Albert Wong, Nicole A. H. Janssen, Maciek Strak, Jurriaan Hoekstra, H. Susan J. Picavet1, H. C.
Hendriek Boshuizen, W. M. Monique Verschuren1& Gerrie‑Cor M. Herber, ―Using random forest to identify
longitudinal predictors of health in a 30‑year cohort study‖ Publishedin Scientific reports (2022) 12:10372, in
(2022)
32. MichałWieczorek,JakubSiłkaID,DawidPołap,MarcinWoźniak,RobertasDamasˇevičiusID,―Real-
timeneuralnetworkbasedpredictorfor cov19virusspread‖, Published on PLOS ONE, (December17,2020),
33. Ian H. ―Data Mining Practical Machine Learning Tools and Techniques, Second Edition,‖ MORGAN
KAUFMANN PUBLISHERS IS AN IMPRINT OF ELSEVIER, second addition, © 2005 by Elsevier Inc
Published in(2005)
34. Alan Brnabicand, Lisa M. Hess ―Systematic literature review of machine learning methods used in the analysis
of real-world data for patient-provider decision making‖ Published on BMC Medical Informatics and
Decision Making, Brnabic and Hess BMC Med Inform Decis Mak (2021).